

Table of contents


No headings in the article.
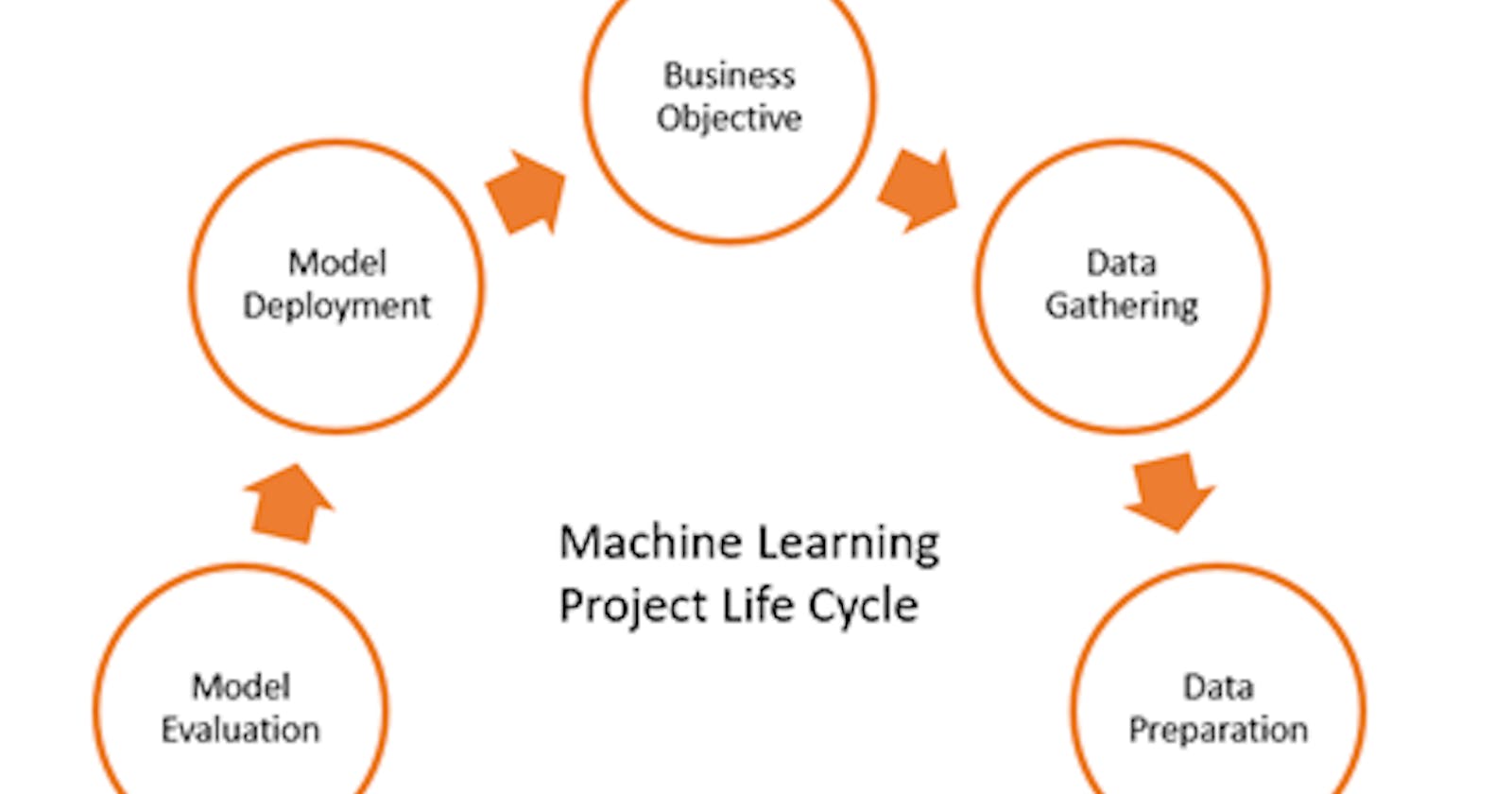
Machine Learning Project Development Project Follows The Given Life Cycle
STEP 1: Framing the real life that our project will be solving
STEP 2: Data Collection Data collection is gathering data for business decision-making, strategic planning, research, and other purposes. The most commonly used methods are:
- Using an API
- Using a database
- Web Scrapping ( using Beautiful Soup in python to scrap out data from the HTML of the Webpage)
- Using a CSV file from Kaggle data set or from the UCI repository
STEP 3: Data Pre-Processing: it involves
1. Finding Missing Values
2. Removing Duplicates
3. Scaling Values
4. Outlier Detection
STEP 4: Exploratory data analysis In this step, our main goal is to find a relationship between input and output. The different types of analysis that we can perform here are
1. Univariate Analysis
2. Bi-Variate Analysis
3. Multivariate Analysis
4. Handling Imbalanced Data Sets
STEP 5: Feature Engineering In this step, we use domain knowledge to create, mutate, delete or combine features so as to improve the machine learning model training leading to better performance and greater accuracy of the model
STEP 6: Model Training, Evaluation and Selection In this step, we select the machine learning model to use , by evaluating various parameters
STEP 7: Model Deployment
STEP 8: Testing & Optimizing the deployed model. For testing we use A/B testing